Usually we use constraints to specify the allowable values for the columns in tables. And it works perfectly! But beyond that, constraints help query analyzer to generate more effective query plans. How does it work? Read below.
There is an opinion "Give MS SQL Server all information you know about data you store." What does it mean? First, obvious things: use the most suitable data type (use int, instead of bigint or float, for example), set the size of strings and binary data (nvarchar(10) instead of nvarchar(max)). And second - the constraints: if the value in a column may be in the range from 1 to 4, you should specify this as a constraint, SQL Server will thank you!
Example
Let's create a table:
CREATE TABLE [TestTable](
[Id] [int] IDENTITY(1,1) NOT NULL,
[Value] [nvarchar](max) NOT NULL,
[Status] [int] NOT NULL
)
Add one million rows with data like this:
Id Value Status
1 value 1
2 value 2
3 value 3
4 value 1
5 value 2
6 value 3
7 value 1
8 value 2
9 value 3
10 value 1
And execute a query (with statistics output):
SET STATISTICS IO ON
SELECT tt.Status, COUNT(*)
FROM [TestTable] AS tt
WHERE tt.Status <> 1
GROUP BY tt.Status
The query is quite real — we need a number of rows in all statuses excluding 1 ("Calc number of orders in all statuses excluding Open").
Query statistics:
Table 'TestTable'. Scan count 9, logical reads 4590, physical reads 0, read-ahead reads 4038, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Execution plan:
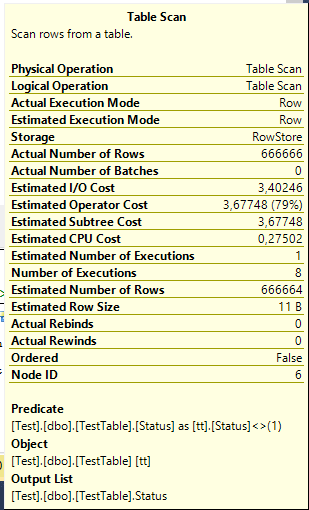
Plain Table Scan — server had to look through a table because it does not have indexes.
Add a new index:
CREATE NONCLUSTERED INDEX [IX_TestTable_Status] ON [TestTable]
(
[Status] ASC
)
And run the query again:
Table 'TestTable'. Scan count 2, logical reads 1501, physical reads 0, read-ahead reads 10, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
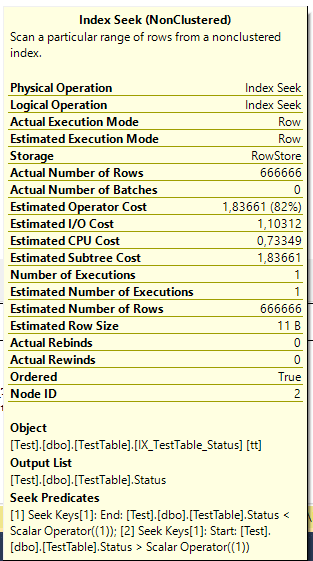
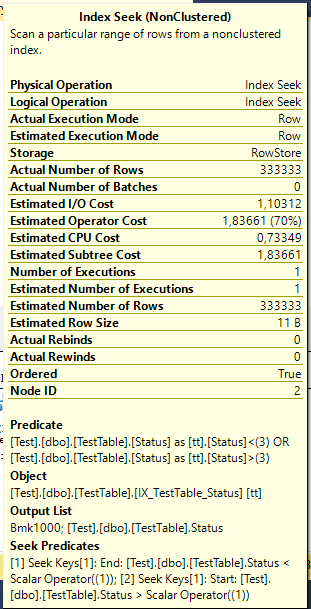
As expected, we see Index Seek with interesting predicate: Staus < 1 и Status > 1. If you remember index is implemented as a tree, and search operation on the tree is quite fast. SQL Server converted inequality into two comparisons that can be processed in the most effective way. Wherein, logical reads are also decreased.
And let's tell SQL Server that column Status can store only values 1, 2, 3 and 4:
ALTER TABLE [TestTable] WITH CHECK ADD CONSTRAINT [CK_TestTable]
CHECK (([Status]=(4) OR [Status]=(3) OR [Status]=(2) OR [Status]=(1)))
Run query:
Table 'TestTable'. Scan count 3, logical reads 1508, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
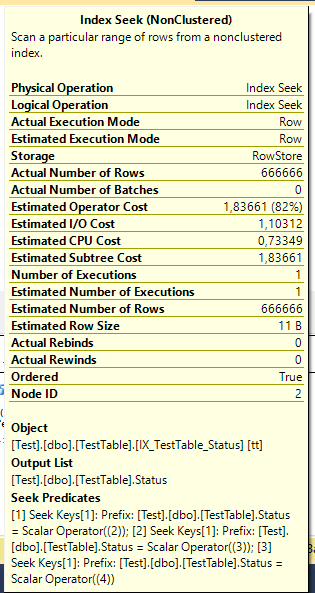
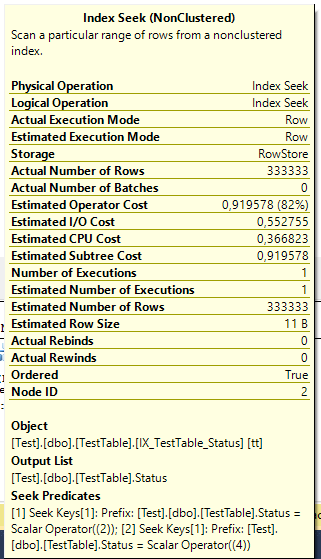
Surprisingly, there is nothing about status "1" in the actual execution plan. Instead of this analyzer replaced <> 1 with predicate IN (2, 3, 4).
But we don't get any advantage in logical reads.
Here is another example with a little bit different query: