MS SQL Server offers several data types for storing strings.
The most popular are nvarchar(N) (1 ≤ N ≤ 4000) and nvarchar(max), which allow storing Unicode-encoded string data.
Application developers often transfer their experience with the string type from programming languages like C# or Java to databases and automatically choose nvarchar(max), which can store strings up to 2GB.
However, databases store and process data in fundamentally different ways.
In this article, I will explain and demonstrate the consequences of unjustified use of the nvarchar(max) type.
Preparation
Let’s create three tables to store text data:
CREATE TABLE [dbo].[nv100]
(
[Id] [int] NOT NULL,
[CreateDate] [datetime] NOT NULL,
[Comment] [nvarchar](100) NOT NULL,
CONSTRAINT [PK_nv100_Id] PRIMARY KEY CLUSTERED ([Id] ASC)
)
CREATE TABLE [dbo].[nv1000]
(
[Id] [int] NOT NULL,
[CreateDate] [datetime] NOT NULL,
[Comment] [nvarchar](1000) NOT NULL,
CONSTRAINT [PK_nv1000_Id] PRIMARY KEY CLUSTERED ([Id] ASC)
)
CREATE TABLE [dbo].[nvmax]
(
[Id] [int] NOT NULL,
[CreateDate] [datetime] NOT NULL,
[Comment] [nvarchar](max) NOT NULL,
CONSTRAINT [PK_nvmax_Id] PRIMARY KEY CLUSTERED ([Id] ASC)
)
The tables differ in the Comment column type. Let’s populate them with 200,000 rows like this:
Id CreateDate Comment
----------- ----------------------- ----------
1 2025-01-01 00:00:01.000 1
2 2025-01-01 00:00:02.000 2
3 2025-01-01 00:00:03.000 3
4 2025-01-01 00:00:04.000 4
5 2025-01-01 00:00:05.000 5
6 2025-01-01 00:00:06.000 6
7 2025-01-01 00:00:07.000 7
8 2025-01-01 00:00:08.000 8
9 2025-01-01 00:00:09.000 9
10 2025-01-01 00:00:10.000 10
Testing Data Select
Let’s select all data from the tables and examine the execution plans:
select *
from nv100
select *
from nv1000
select *
from nvmax
At first glance, all three plans look identical:
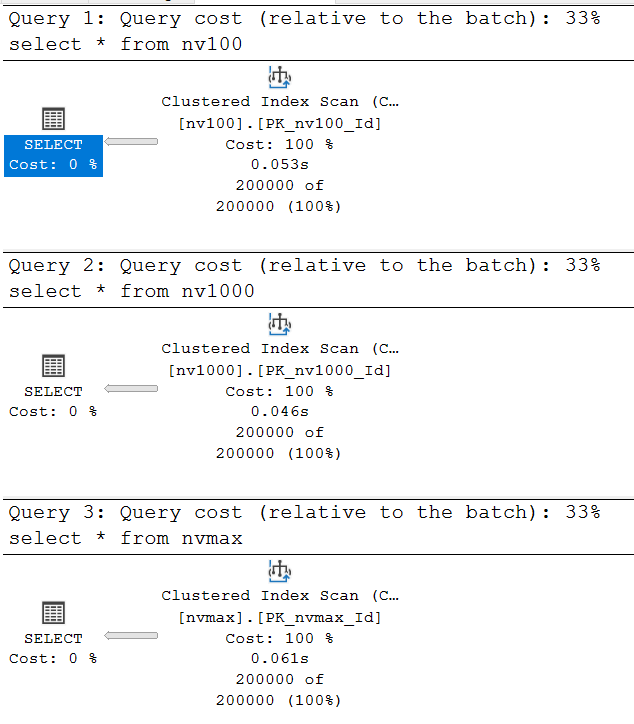
Let’s look at the single arrow in the first query’s plan:
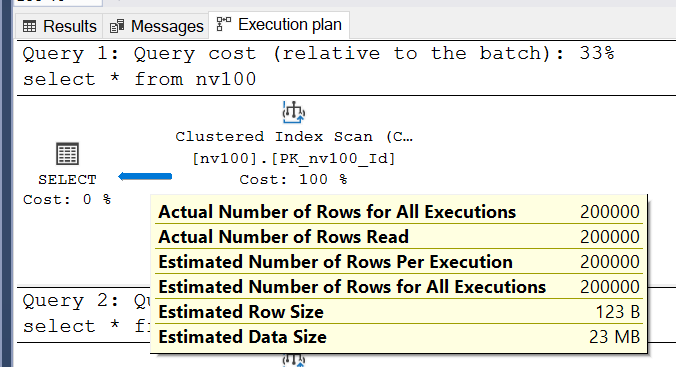
SQL Server correctly estimated the number of rows to return: 200,000.
This is predictable since we’re selecting all data from the table.
The more interesting metric is Estimated Row Size — the estimated size of one row in bytes.
How is this calculated? It includes row metadata and the actual data. For our case: 4 bytes for the int identifier, 8 bytes for the datetime field, and according to documentation, nvarchar(n) requires 2*n bytes. For nvarchar(100), this is 200 bytes. Total: 4 + 8 + 200 = 212 bytes. Why does SQL Server estimate 123 bytes?
When generating the query plan, SQL Server estimates nvarchar(n) columns as half their maximum byte size. Thus, 100 bytes for the first table. The estimated row size becomes 4 + 8 + 100 = 112 bytes, plus metadata. Let’s check the second table’s plan:
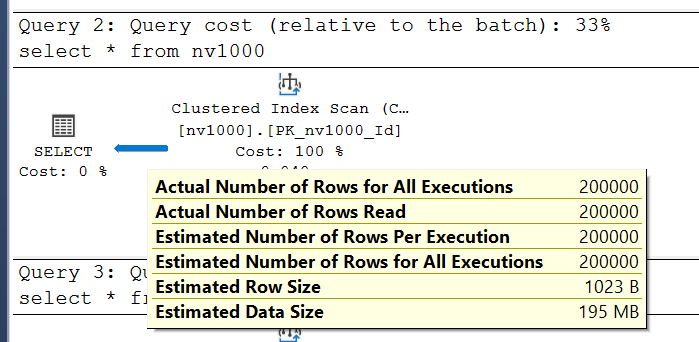
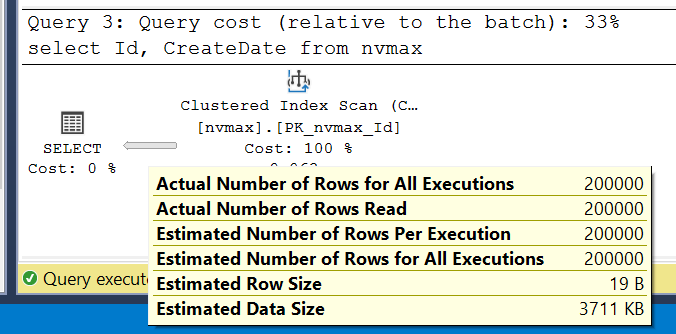
Here, Estimated Row Size increases to 1023 bytes, with 4 + 8 + 1000 = 1012 bytes for data. For nvarchar(max), which can store up to 2GB, does SQL Server estimate 1GB per row? No, it uses 4000 bytes as the default estimate:

If we exclude the Comment column, SQL Server provides accurate estimates:
select Id, CreateDate
from nvmax
Sorting
When compiling a query plan, SQL Server considers factors like table size, indexes, data types, and Estimated Row Size to determine memory allocation and whether to use TempDB (e.g., for sorting large datasets).
Let’s sort the data by Comment:
select *
from nv100
order by Comment desc
select *
from nv1000
order by Comment desc
select *
from nvmax
order by Comment desc
Execution plans:
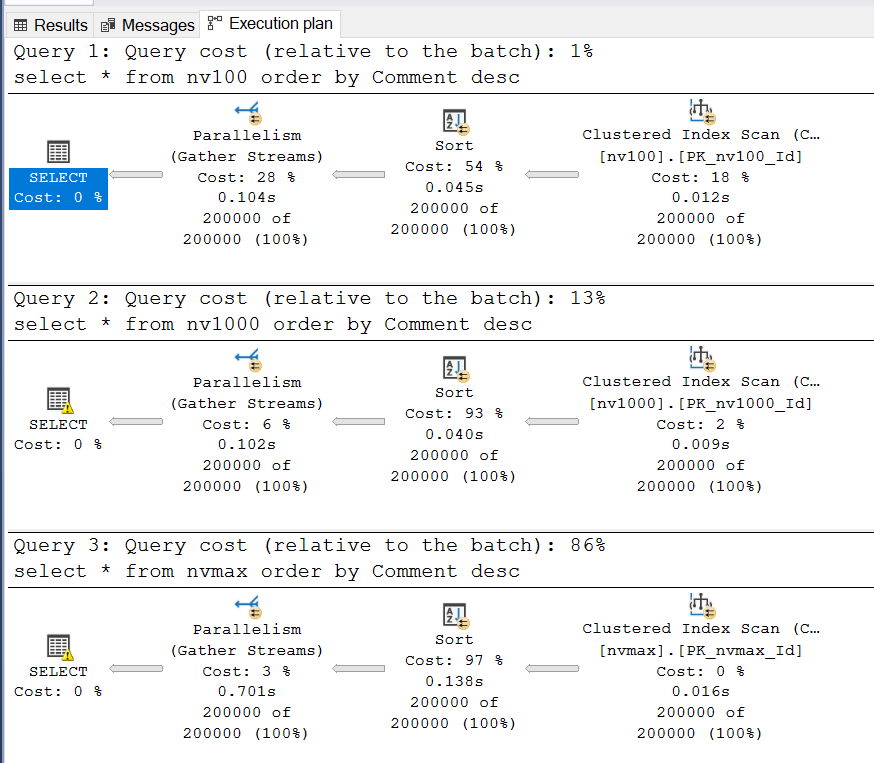
The plans appear similar, but the second query shows a warning (Excessive Grant) on the SELECT operator:
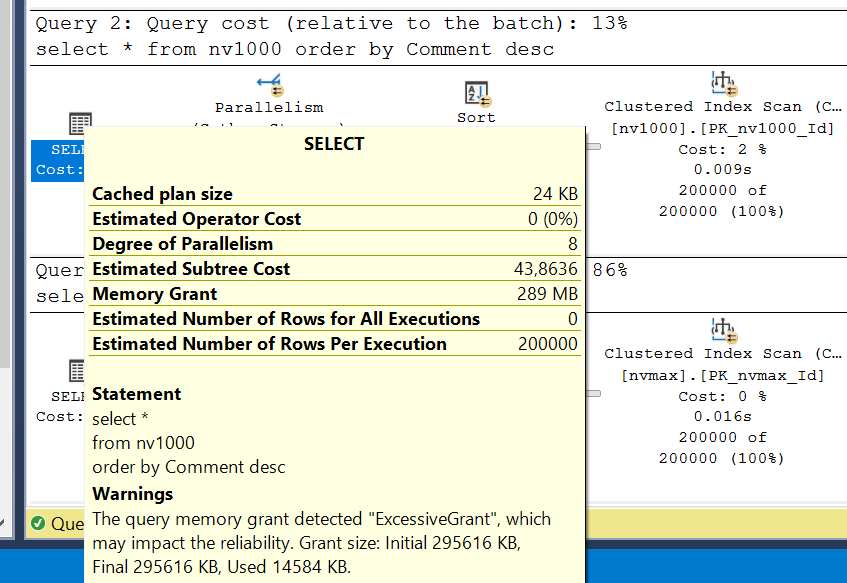
SQL Server requested 295,616 KB (~300 MB) for execution but used only 14,584 KB (~15 MB) — 20 times less. The third query is worse:
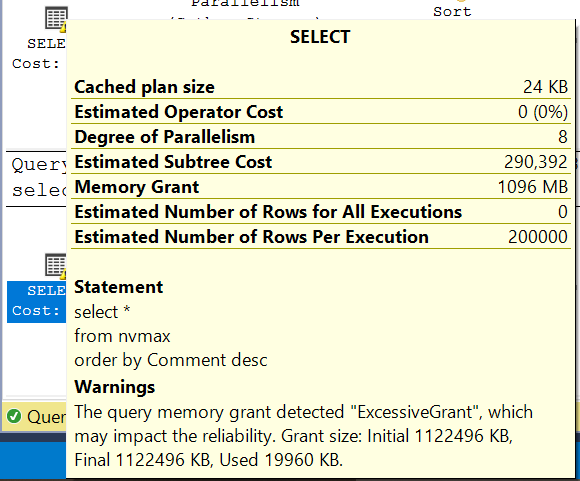
It requested 1,122,496 KB (~1.1 GB) but used only 19,960 KB (~20 MB) — 56 times less. This unnecessary memory allocation can deprive other queries of resources.
Filtering
Let’s filter by the Comment column:
select *
from nv100
where Comment = N'12345'
select *
from nv1000
where Comment = N'12345'
select *
from nvmax
where Comment = N'12345'
Execution plans:
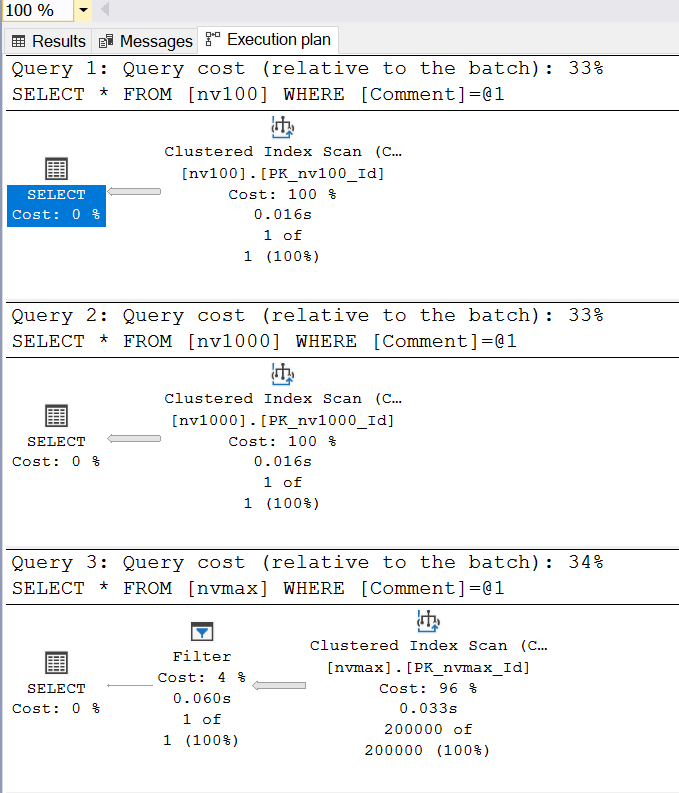
All queries scan the clustered index, but the nvmax table has an extra Filter operation. Why? nvarchar(max) data can be stored in two ways:
IN_ROW_DATA: Stored directly in the row if ≤ 8000 bytes.LOB_DATA: Stored in separate pages if > 8000 bytes, with a pointer in the row.
Check storage types:
SELECT
t.Name as TableName,
a.type_desc as StorageType
FROM sys.tables t
JOIN sys.columns c ON t.object_id = c.object_id
JOIN sys.partitions p ON t.object_id = p.object_id
JOIN sys.allocation_units a ON p.partition_id = a.container_id
WHERE c.system_type_id = 231 -- nvarchar(max)
AND a.type_desc IN ('IN_ROW_DATA', 'LOB_DATA')
Result:
TableName StorageType
---------- -------------
nv100 IN_ROW_DATA
nv1000 IN_ROW_DATA
nvmax IN_ROW_DATA
nvmax LOB_DATA
For nvmax, data is stored in both formats, forcing SQL Server to retrieve data before applying filters, hence the extra Filter step.
Indexes
You cannot create an index on nvarchar(max). Attempting to index nvarchar(1000) generates a warning:
CREATE NONCLUSTERED INDEX [IX_nv1000_Comment] ON [dbo].[nv1000]
(
[Comment] ASC
)
Warning! The maximum key length for a nonclustered index is 1700 bytes. The index 'IX_nv1000_Comment' has maximum length of 2000 bytes. For some combination of large values, the insert/update operation will fail.
Inserting a 1000-character string fails:
insert into nv1000
values(-1, GETUTCDATE(), REPLICATE(N'A',1000))
Msg 1946, Level 16, State 3, Line 1
Operation failed. The index entry of length 2000 bytes for the index 'IX_nv1000_Comment' exceeds the maximum length of 1700 bytes for nonclustered indexes.
Comparison
| nvarchar(100) | nvarchar(1000) | nvarchar(max) | |
|---|---|---|---|
| Data Storage | IN_ROW_DATA | IN_ROW_DATA | IN_ROW_DATA/LOB_DATA |
| Estimated Row Size | 100 bytes | 1000 bytes | 4000 bytes |
| Index Support | Yes | Yes (with restrictions) | No |
Conclusions
- The
ninnvarchar(n)is not just a maximum length — it helps SQL Server optimize query plans. - Use
nvarchar(max)only for genuinely large strings. Apply business logic constraints (e.g., user input limits) to the database. - The optimal
nvarchar(n)size is twice the average stored string length.