Dapper is a popular library that allows mapping objects from a database to C# types. Unlike Entity Framework, it is not a full-fledged ORM, but it is very popular due to its minimalism. In this article, I will explain how the default behavior can lead to a significant increase in memory consumption.
Profiling
This story began with one application at work. Metrics showed that over time it consumed more and more memory, although there were no obvious reasons for it. I collected an application dump and opened it in a profiler.
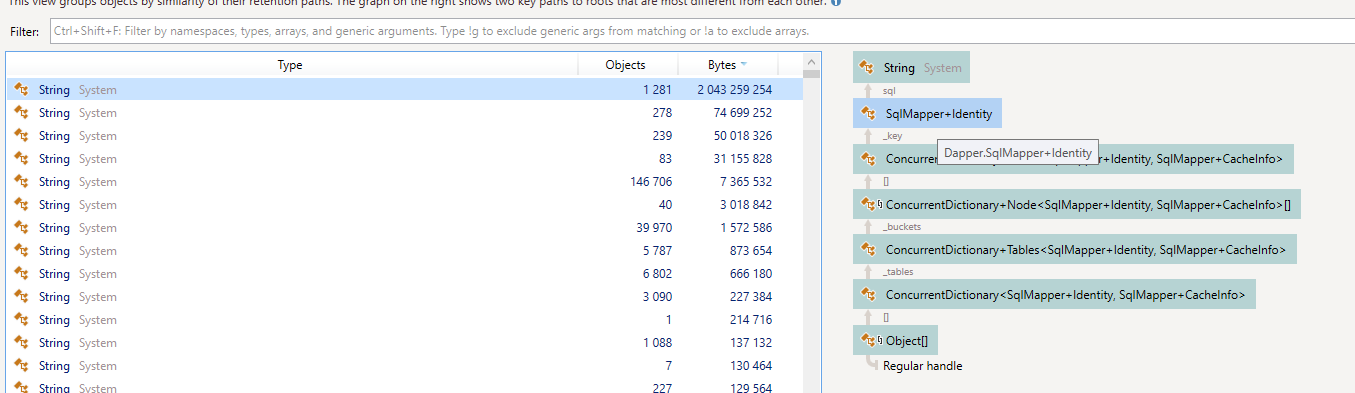 The problem was visible almost immediately — the application was holding 2 gigabytes of some strings in memory, related to Dapper.
The strings themselves contained the body of the SQL query. Let's study what objects in memory they are associated with.
The problem was visible almost immediately — the application was holding 2 gigabytes of some strings in memory, related to Dapper.
The strings themselves contained the body of the SQL query. Let's study what objects in memory they are associated with.
Dapper internals
The profiler points to the SqlMapper.Identity type and the associated SqlMapper.CacheInfo. From the name, it's obvious that it is about caching.
Let's take a closer look at the creation of the SqlMapper.Identity type during query execution:
private static async Task<int> ExecuteImplAsync(
IDbConnection cnn,
CommandDefinition command,
object? param)
{
SqlMapper.CacheInfo cacheInfo = SqlMapper.GetCacheInfo(new SqlMapper.Identity(command.CommandText, new CommandType?(command.CommandTypeDirect), cnn, (Type) null, param?.GetType()), param, command.AddToCache);
// ...
}
As we can see, at the beginning of the method, we try to get something from the cache using SqlMapper.Identity as a key, which contains the full text of the query in command.CommandText and other parameters.
The type stored in the cache is SqlMapper.CacheInfo:
private class CacheInfo
{
private int hitCount;
public SqlMapper.DeserializerState Deserializer { get; set; }
public Func<DbDataReader, object>[]? OtherDeserializers { get; set; }
public Action<IDbCommand, object?>? ParamReader { get; set; }
public int GetHitCount() => Interlocked.CompareExchange(ref this.hitCount, 0, 0);
public void RecordHit() => Interlocked.Increment(ref this.hitCount);
}
This is a set of different deserializers associated with a specific SQL query, which allows Dapper to reuse objects for similar queries, speeding up data materialization.
A fairly reasonable optimization. But why is our application holding such a large cache?
SQl + json = 🚩
The problem is how we construct the SQL query. For example, the method for getting users by a list of identifiers looks like this:
public async Task<ICollection<string>> SearchAsync(
ThemeSearchRequest searchRequest,
int skip = 0,
int take = int.MaxValue,
TimeSpan? timeout = null)
{
var selectScript = @$"SELECT theme_base
FROM [dbo].Themes
{searchRequest.ToWhereExpression()}
GROUP BY theme_base
ORDER BY MAX(count_base) DESC, theme_base
OFFSET {skip} ROWS
FETCH NEXT {take} ROWS ONLY";
await using var connection = new SqlConnection(this.connectionString);
var result = (await connection.QueryAsync<string>(
selectScript,
searchRequest.ToParametersWithValues(),
commandTimeout: (int)(timeout?.TotalSeconds ?? DefaultTimeout.TotalSeconds))).AsList();
return result;
}
The SearchAsync method forms a dynamic query to the database — some search conditions, pagination. And that's the problem.
Almost every query will be unique, and according to Dapper's basic logic, it will be cached for fast materialization in the future.
The same is written in the documentation:
Dapper caches information about every query it runs, this allows it to materialize objects quickly and process parameters quickly. The current implementation caches this information in a ConcurrentDictionary object. Statements that are only used once are routinely flushed from this cache. Still, if you are generating SQL strings on the fly without using parameters it is possible you may hit memory issues.
Dapper caching
Let's take a closer look at the caching mechanism in Dapper. We have already found out that each SQL query is used as a key and stores additional information for fast materialization of objects.
Will this cache grow indefinitely? Let's look at the SqlMapper code:
private static bool TryGetQueryCache(Identity key, [NotNullWhen(true)] out CacheInfo? value)
{
if (_queryCache.TryGetValue(key, out value!))
{
value.RecordHit();
return true;
}
value = null;
return false;
}
The TryGetQueryCache method searches for data in the cache and, if successful, increments the hit counter — the number of times the data has been returned for this key.
private const int COLLECT_PER_ITEMS = 1000;
private static void SetQueryCache(Identity key, CacheInfo value)
{
if (Interlocked.Increment(ref collect) == COLLECT_PER_ITEMS)
{
CollectCacheGarbage();
}
_queryCache[key] = value;
}
The SetQueryCache method tries to add data to the cache until it reaches a size of 1000 elements.
When this limit is reached, the CollectCacheGarbage() method is called:
private const int COLLECT_HIT_COUNT_MIN = 0;
private static void CollectCacheGarbage()
{
try
{
foreach (var pair in _queryCache)
{
if (pair.Value.GetHitCount() <= COLLECT_HIT_COUNT_MIN)
{
_queryCache.TryRemove(pair.Key, out var _);
}
}
}
finally
{
Interlocked.Exchange(ref collect, 0);
}
}
It tries to remove all cached items that have never been accessed. In this process, the GetHitCount() method resets the internal hit counter:
public int GetHitCount() { return Interlocked.CompareExchange(ref hitCount, 0, 0); }
Thus, after CollectCacheGarbage() is run, the value of all hitCounts is reset, which allows finding unused elements during the next cleanup.
But in the case of active use of dynamic SQL queries, it is highly likely that all queries will be used once and will be constantly evicted from the cache.
Using one-time queries not only hits your application's memory but also creates an additional load on the SQL server. It will have to parse, compile, and build an execution plan for each new query.
Solution
The correct solution here would be to use parameterized queries so that a single query will be reused many times, including on the SQL server:
public async Task<ICollection<TaskRules>> GetTaskRulesAsync(long taskId)
{
var sql = $@"SELECT * FROM TaskRules WHERE TaskID = @taskId";
await using var connection = new SqlConnection(this.connectionString);
await connection.OpenAsync();
var result = await connection
.QueryAsync<TaskRules>(sql, new { taskId }, commandTimeout: 180);
return result.AsList();
}
The GetTaskRulesAsync method uses a parameterized SQL query, where data is selected by @taskId.
This allows using caching at all levels — in the application and on the SQL server.
A quick solution might be to disable caching for a specific query — this can be done by managing CommandFlags when creating the command:
new CommandDefinition(sql, CommandFlags.NoCache)
This way, "one-time" queries will not get into the cache and clutter up the memory.
Conclusion
Many solutions try to optimize frequently used scenarios through strict rules or some of their own heuristics. Such important rules are usually described somewhere prominently. In Dapper's case — right in the Readme.md.
Recommendations
- Perform periodic profiling, see how applications use memory. For example, using dotMemory.
- Use parameterized queries for working with SQL.
- If any solution uses caching, make sure it is useful for you.