MS SQL Server предоставляет нам на выбор несколько типов данных для хранения строк. Самый популярный - nvarchar(N) (где 1 ≤ N ≤ 4000) или nvarchar(max), который позволяет хранить строковые данные в кодировке Юникод. При этом, часто прикладные разработчики переносят опыт использования типа string из языка приложения (C# или Java, например) в базы данных и не задумываясь выбирают тип nvarchar(max), позволяющий хранить строки размером до 2ГБ. Но базы данных хранят и работают с данными совершенно другим способом. В этой статье я расскажу и покажу на практике, к чему может приводить неоправданное использование типа nvarchar(max).
Подготовка
Давайте создадим 3 таблицы, хранящие текстовые данные:
CREATE TABLE [dbo].[nv100]
(
[Id] [int] NOT NULL,
[CreateDate] [datetime] NOT NULL,
[Comment] [nvarchar](100) NOT NULL,
CONSTRAINT [PK_nv100_Id] PRIMARY KEY CLUSTERED ([Id] ASC)
)
CREATE TABLE [dbo].[nv1000]
(
[Id] [int] NOT NULL,
[CreateDate] [datetime] NOT NULL,
[Comment] [nvarchar](1000) NOT NULL,
CONSTRAINT [PK_nv1000_Id] PRIMARY KEY CLUSTERED ([Id] ASC)
)
CREATE TABLE [dbo].[nvmax]
(
[Id] [int] NOT NULL,
[CreateDate] [datetime] NOT NULL,
[Comment] [nvarchar](max) NOT NULL,
CONSTRAINT [PK_nvmax_Id] PRIMARY KEY CLUSTERED ([Id] ASC)
)
Таблицы отличаются типом колонки Comment. Заполним эти таблицы 200 000 строками подобного вида:
Id CreateDate Comment
----------- ----------------------- ----------
1 2025-01-01 00:00:01.000 1
2 2025-01-01 00:00:02.000 2
3 2025-01-01 00:00:03.000 3
4 2025-01-01 00:00:04.000 4
5 2025-01-01 00:00:05.000 5
6 2025-01-01 00:00:06.000 6
7 2025-01-01 00:00:07.000 7
8 2025-01-01 00:00:08.000 8
9 2025-01-01 00:00:09.000 9
10 2025-01-01 00:00:10.000 10
Тестируем выборки
Просто выберем все данные из таблиц и посмотрим на план выполнения:
select *
from nv100
select *
from nv1000
select *
from nvmax
На первый взгляд мы получаем 3 одинаковых плана:
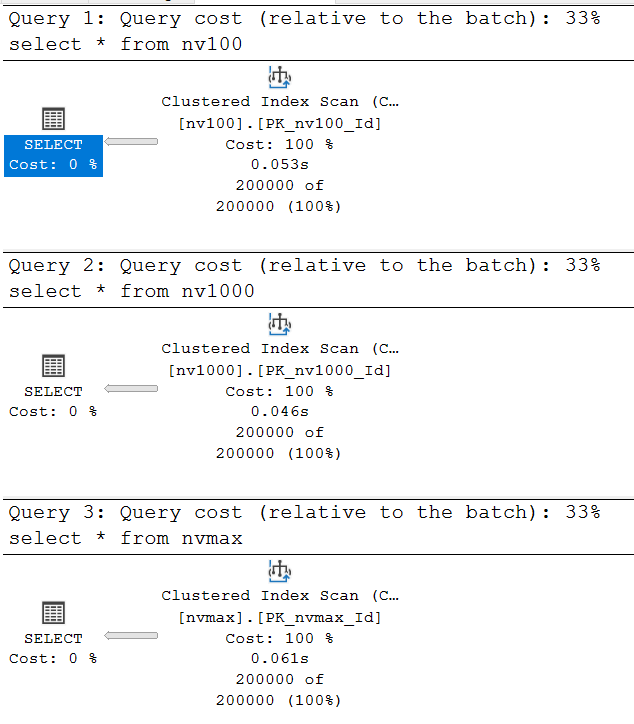
Давайте посмотрим на единственную стрелочку в плане первого запроса:
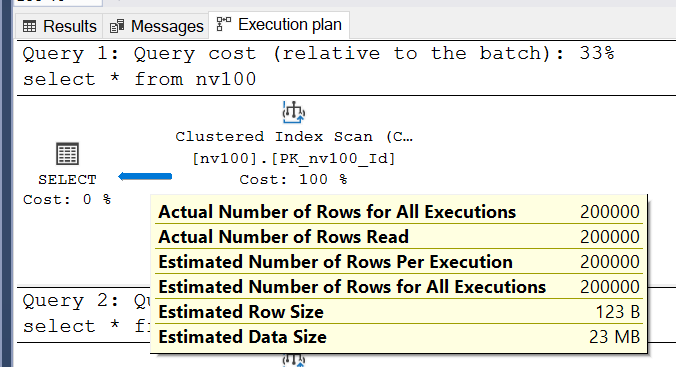
Мы видим, что SQL Server правильно определил количество строк, которые необходимо вернуть - 200 000. Это предсказуемо, т.к. мы выбираем все данные из таблицы.
Более интересный показатель Estimated Row Size - предполагаемый размер одной строки в байтах. Из чего он складывается? Это метаданные, которые есть в каждой строке и непосредственно сами данные. В нашем случае 4 байта отводится под идентификатор типа int, 8 байт для поля типа datetime и из документации мы знаем, что тип nvarchar(n) занимает 2*n байт. Для колонки с типом nvarchar(100) будет 200 байт. 4 + 8 + 200 = 212 байт. Почему же SQL Server оценивает размер в 123 байта?
При составлении плана запроса сервер делает оценку по полю nvarchar(n) как половину от максимально возможного количества байт. Т.е. 100 байт для первой таблицы. Таким образом, предполагаемый объем занимаемых данных в одной строке - 4 + 8 + 100 = 112 байт. Еще несколько байт занимают метаданные. Давайте посмотрим на план запроса для второй таблицы:
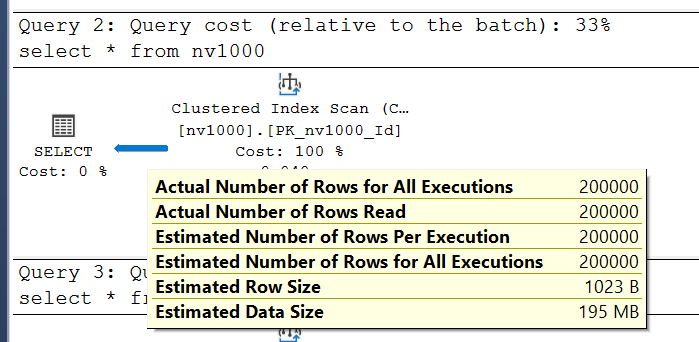
Видим, что Estimated Row Size вырос до 1023 байт, из которых на данные отводится теперь 4 + 8 + 1000 = 1012 байт, остальное - опять метаданные. А что же будет для типа nvarchar(max)? Данный тип данных позволяет хранить до 2ГБ. Неужели, каждая строка будет получать оценку в 1ГБ данных? На самом деле нет, SQL Server оценивает такие данные в 4000 байт:

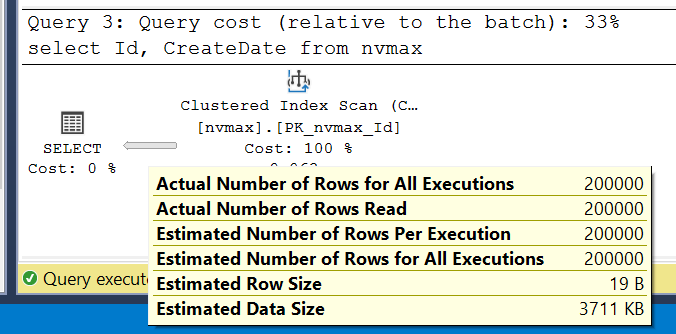
Если мы исключим колонку Comment из выборки, то SQL Server будет делать точные оценки:
select Id, CreateDate
from nvmax
Сортировка
Как мы знаем, перед выполнением запроса SQL Server пытается оставить оптимальный план - то, как именно получить данные, какие алгоритмы использовать. На составление плана влияет множество параметров: размеры таблиц, наличие индексов, типы данных и многое другое... Один из таких влияющих параметров - Estimated Row Size. Опираясь на него SQL Server определяет, сколько оперативной памяти нужно выделить под выполнение определенного запроса и нужно ли использовать TempDB (например, для сортировки больших данных).
Давайте проверим это на примере и отсортируем нашу выборку по комментарию:
select *
from nv100
order by Comment desc
select *
from nv1000
order by Comment desc
select *
from nvmax
order by Comment desc
И посмотрим на план выполнения:
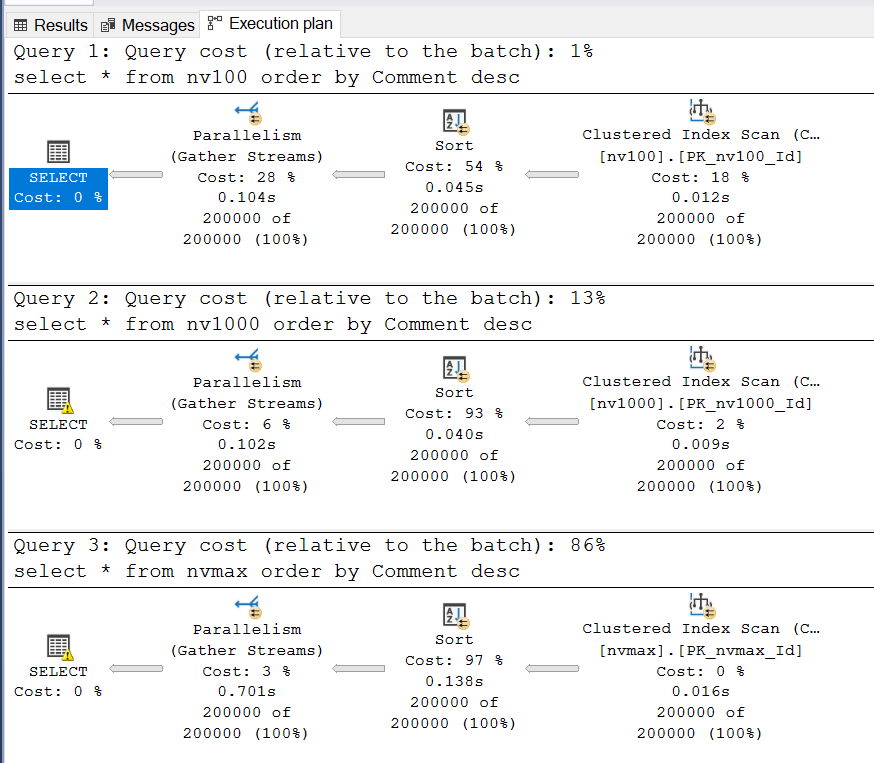
Получаются очень похожие планы, но обратите внимание на восклицательный знак возле оператора SELECT во втором запросе - там явно есть какая-то проблема:
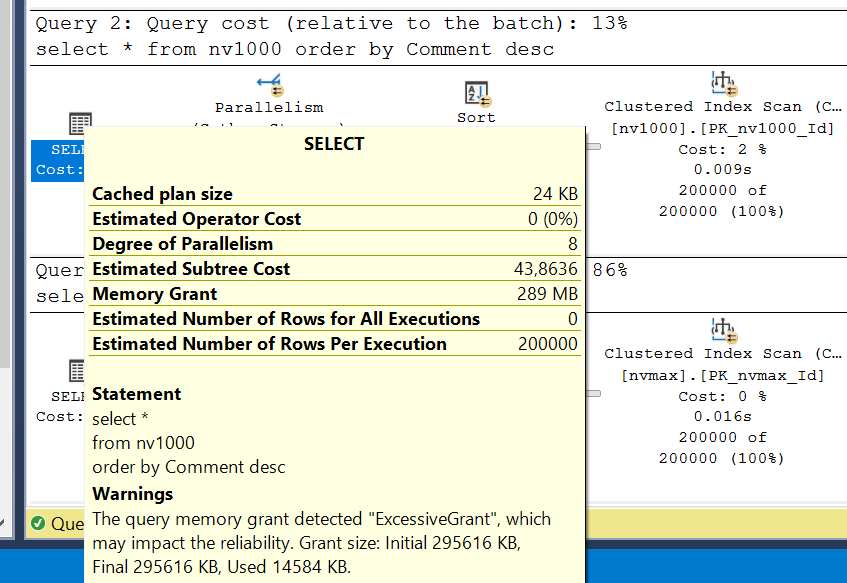
Мы видим предупреждение типа Excessive Grant. Основываясь на оценках объема данных SQL Server запросил для выполнения запроса 295616 килобайт (~300 мегабайт), а фактически было использовано всего 14584 килобайт (~15 мегабайт), т.е. в 20 раз меньше.
Еще хуже ситуация с третьим запросом:
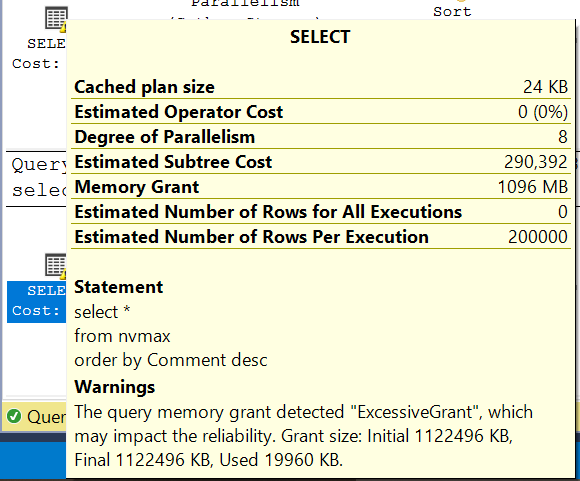
Запросив 1122496 килобайт (~1.1 гигабайт), было использовано всего 19960 килобайт (~20 мегабайт) - в 56 раз меньше. Фактически, мы заставили SQL Server выделить лишний гигабайт памяти, который никак не был использован. Как минимум, это не полезно, а в худшем случае - может отнять ресурсы у более полезного запроса.
Фильтрация
Давайте сделаем выборку с фильтрацией по полю Comment:
select *
from nv100
where Comment = N'12345'
select *
from nv1000
where Comment = N'12345'
select *
from nvmax
where Comment = N'12345'
И традиционно посмотрим на план выполнения:
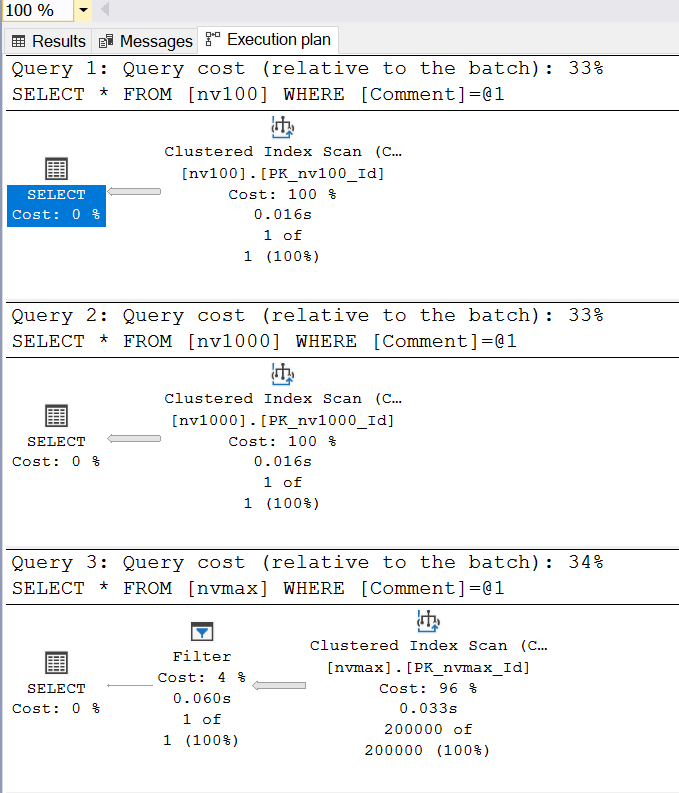
Во всех случаях мы полностью сканируем кластерный индекс, но бросается в глаза, что в случае с таблицей nvmax появляется дополнительная операция Filter. Почему так? Причина в способе хранения данных. Данные типа nvarchar(max) могут храниться двумя разными способами:
IN_ROW_DATA- если данные меньше или равны 8000 байт, то они хранятся непосредственно в строке таблицы.LOB_DATA- если данные превышают 8000 байт, то они хранятся в отдельных страницах внутри файлов базы данных. В строке остаётся только указатель на эти данные.
В нашей колонке Comment данные значительно меньше 8000 байт, но SQL Server мог по другим причинам разместить данные в LOB_DATA. Давайте проверим, где именно располагаются данные:
SELECT
t.Name as TableName,
a.type_desc as StorageType
FROM sys.tables t
JOIN sys.columns c ON t.object_id = c.object_id
JOIN sys.partitions p ON t.object_id = p.object_id
JOIN sys.allocation_units a ON p.partition_id = a.container_id
WHERE c.system_type_id = 231 -- nvarchar(max)
AND a.type_desc IN ('IN_ROW_DATA', 'LOB_DATA')
Результат запроса:
TableName StorageType
---------- -------------
nv100 IN_ROW_DATA
nv1000 IN_ROW_DATA
nvmax IN_ROW_DATA
nvmax LOB_DATA
Видим, что для таблиц nv100 и nv1000 данные хранятся только в режиме IN_ROW_DATA. Для таблицы nvmax используются оба варианта (IN_ROW_DATA, LOB_DATA).
Возвращаясь к запросу с фильтрацией, такое расположение данных приводит к тому, что серверу предварительно требуется извлечь данные, а только потом применить фильтрацию. От этого в плане запроса мы видим дополнительную операцию Filter.
Индексы
Да, поиск по строке, не самый частый сценарий. А если это и требуется, то логично создать индекс. Но тут очевидное ограничение, на колонку с типом nvarchar(max) нельзя создать индекс. Более того, при попытке создать индекс на колонку с типом nvarchar(1000) мы получим предупреждение:
CREATE NONCLUSTERED INDEX [IX_nv1000_Comment] ON [dbo].[nv1000]
(
[Comment] ASC
)
Warning! The maximum key length for a nonclustered index is 1700 bytes. The index 'IX_nv1000_Comment' has maximum length of 2000 bytes. For some combination of large values, the insert/update operation will fail.
Индекс будет работать только для определенных данных. При попытке вставить строку максимальной длины мы получим ошибку:
insert into nv1000
values(-1, GETUTCDATE(), REPLICATE(N'A',1000))
Msg 1946, Level 16, State 3, Line 1
Operation failed. The index entry of length 2000 bytes for the index 'IX_nv1000_Comment' exceeds the maximum length of 1700 bytes for nonclustered indexes.
Сравнение
| nvarchar(100) | nvarchar(1000) | nvarchar(max) | |
|---|---|---|---|
| Хранение данных | IN_ROW_DATA | IN_ROW_DATA | IN_ROW_DATA/LOB_DATA |
| Оценка размера строки | 100 байт | 1000 байт | 4000 байт |
| Индекс | Да | Да, с ограничениями | Нет |
Выводы
- Число
nв определении типаnvarchar(n)- не просто ограничение максимальной длины строки. Это важная информация, которая помогает SQL Server'у выбирать наиболее оптимальный план запроса. - Использование
nvarchar(max)должно быть оправдано и использоваться для действительно больших строк. Скорее всего, ваша бизнес-логика ограничивает максимальную длину строки в приложении. Если это пользовательский ввод или API - там наверняка будут ограничения. Перенесите эти ограничения на базу данных. - Оптимальным размером для типа
nvarchar(n)будет удвоенная средняя длина хранящихся строк.