Dapper — популярная библиотека, которая позволяет делать маппинг объектов из базы данных в типы C#. В отличие от Entity Framework не является полноценной ORM, но пользуется большой популярностью за счет своей минималистичности. В этой статье я расскажу, как поведение по-умолчанию может привести к значительному росту потребления памяти.
Профилирование
Эта история началась с одного приложения на работе. Метрики показывали, что со временем оно потребляло всё больше и больше памяти, хотя явных причин на то не было. Я собрал дамп приложения и открыл его в профайлере.
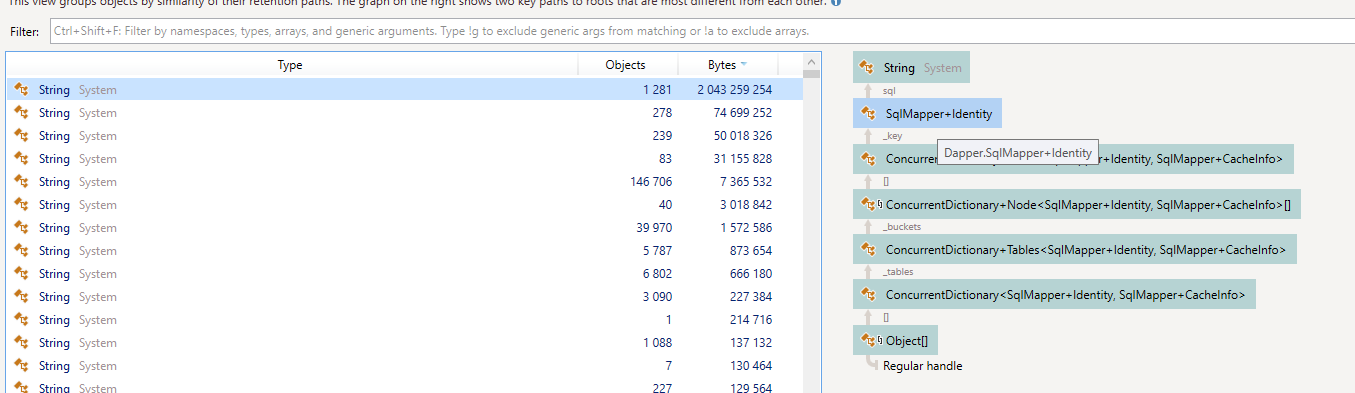
Проблема была видна практически сразу — приложение держало в памяти 2 гигабайта каких-то строк, связанных с Dapper. Сами строки содержали в себе тело SQL-запроса. Давайте посмотрим, с какими объектами в памяти они ассоциированы.
Внутренности Dapper
Профайлер указывает нам на тип SqlMapper.Identity и связанынй с ним SqlMapper.CacheInfo. По названию очевидно, что это своего рода кеширование.
Давайте ближе взглянем на создание типа SqlMapper.Identity в процессе выполнения запроса:
private static async Task<int> ExecuteImplAsync(
IDbConnection cnn,
CommandDefinition command,
object? param)
{
SqlMapper.CacheInfo cacheInfo = SqlMapper.GetCacheInfo(new SqlMapper.Identity(command.CommandText, new CommandType?(command.CommandTypeDirect), cnn, (Type) null, param?.GetType()), param, command.AddToCache);
// ...
}
Как мы видим, в самом начале метода мы пытаемся получить что-то из кэша используя для этого в качестве ключа SqlMapper.Identity,
который в свою очередь содержит полный текст запроса command.CommandText и другие параметры.
Хранится в кеше тип SqlMapper.CacheInfo:
private class CacheInfo
{
private int hitCount;
public SqlMapper.DeserializerState Deserializer { get; set; }
public Func<DbDataReader, object>[]? OtherDeserializers { get; set; }
public Action<IDbCommand, object?>? ParamReader { get; set; }
public int GetHitCount() => Interlocked.CompareExchange(ref this.hitCount, 0, 0);
public void RecordHit() => Interlocked.Increment(ref this.hitCount);
}
Это набор разных десериализаторов ассоциированных с конкретным SQL-запросом, что позволяет Dapper переиспользовать объекты для однотипных запросов ускоряя материализацию данных.
Довольно разумная оптимизация. Но почему же наше приложение держит такой большой кэш?
SQl + json = 🚩
Проблема в том, как именно мы составляем SQL запрос. Например, метод получения пользователей по списку идентификаторов выглядит так:
public async Task<ICollection<string>> SearchAsync(
ThemeSearchRequest searchRequest,
int skip = 0,
int take = int.MaxValue,
TimeSpan? timeout = null)
{
var selectScript = @$"SELECT theme_base
FROM [dbo].Themes
{searchRequest.ToWhereExpression()}
GROUP BY theme_base
ORDER BY MAX(count_base) DESC, theme_base
OFFSET {skip} ROWS
FETCH NEXT {take} ROWS ONLY";
await using var connection = new SqlConnection(this.connectionString);
var result = (await connection.QueryAsync<string>(
selectScript,
searchRequest.ToParametersWithValues(),
commandTimeout: (int)(timeout?.TotalSeconds ?? DefaultTimeout.TotalSeconds))).AsList();
return result;
}
Метод SearchAsync формирует динамический запрос к базе — какие-то поисковые условия, пагинация. И в этом и есть проблема.
Почти каждый запрос будет уникальным, и согласно базовой логике Dapper он будет кешироваться для быстрой материализации в будущем.
Об этом же написано в документации:
Dapper caches information about every query it runs, this allows it to materialize objects quickly and process parameters quickly. The current implementation caches this information in a ConcurrentDictionary object. Statements that are only used once are routinely flushed from this cache. Still, if you are generating SQL strings on the fly without using parameters it is possible you may hit memory issues.
Кеширование Dapper
Давайте подробнее рассмотрим механизм кеширование в Dapper. Мы уже выяснили, что каждый SQL-запрос используется в качестве ключа и сохраняет дополнительную информацию для быстрой материализации объектов.
Будет ли этот кэш расти бесконечно? Давайте взглянем на код SqlMapper:
private static bool TryGetQueryCache(Identity key, [NotNullWhen(true)] out CacheInfo? value)
{
if (_queryCache.TryGetValue(key, out value!))
{
value.RecordHit();
return true;
}
value = null;
return false;
}
Метод TryGetQueryCache ищет данные в кэше и в случае успеха увеличивает счетчик попаданий — количество раз, котоыре данные возвращались по этому ключу.
private const int COLLECT_PER_ITEMS = 1000;
private static void SetQueryCache(Identity key, CacheInfo value)
{
if (Interlocked.Increment(ref collect) == COLLECT_PER_ITEMS)
{
CollectCacheGarbage();
}
_queryCache[key] = value;
}
Метод SetQueryCache пытается добавить данные в кэш, пока он не достиг размера в 1000 элементов.
В случае его достижения вызывается метод CollectCacheGarbage():
private const int COLLECT_HIT_COUNT_MIN = 0;
private static void CollectCacheGarbage()
{
try
{
foreach (var pair in _queryCache)
{
if (pair.Value.GetHitCount() <= COLLECT_HIT_COUNT_MIN)
{
_queryCache.TryRemove(pair.Key, out var _);
}
}
}
finally
{
Interlocked.Exchange(ref collect, 0);
}
}
Он пытается удалить все закешированные элементы, к которым ни разу не обращались. При этом, метод GetHitCount() обнуляет внутренний счетчик попаданий:
public int GetHitCount() { return Interlocked.CompareExchange(ref hitCount, 0, 0); }
Таким образом, после запуска CollectCacheGarbage() значение всех hitCount обнуляется, что позволяет найти неиспользуемые элементы при следующей очистке.
Но в случае активного использования динамических SQL-запросов велика вероятность, что все запросы будут использоваться по 1 разу и постоянно будут вытесняться из кэша.
Использование одноразовых запросов бьет не только по памяти вашего приложения, но и создаёт дополнительную нагрузку на SQL-сервер. Ему придется парсить, компилировать и строить план выполнения для каждого нового запроса.
Решение
Корректным вариантом решения здесь было бы использование параметризованных, тогда один запрос будет переиспользоваться множество раз, в том числе и на SQL-сервере:
public async Task<ICollection<TaskRules>> GetTaskRulesAsync(long taskId)
{
var sql = $@"SELECT * FROM TaskRules WHERE TaskID = @taskId";
await using var connection = new SqlConnection(this.connectionString);
await connection.OpenAsync();
var result = await connection
.QueryAsync<TaskRules>(sql, new { taskId }, commandTimeout: 180);
return result.AsList();
}
В методе GetTaskRulesAsync используется параметризованный SQL-запрос, где выбираются данные по @taskId.
Это позволяет эффективно использовать кеширование на всех уровнях — в приложении и SQL-сервере.
Быстрым решением может быть отключение кеширования для конкретного запроса — это можно сделать через управление CommandFlags при создании команды:
new CommandDefinition(sql, CommandFlags.NoCache)
Таким образом, "одноразовые" запросы не будут попадать в кэш и засорять память.
Заключение
Многие решения пытаются оптимизировать часто-используемые сценарии за счет строгих правил или каких-то своих эвристик. Такие важные правила обычно описаны где-то на видном месте. В случае в Dapper — сразу в Readme.md.
Рекомендации
- Проводите периодическое профилирование, смотрите, как приложения используют память. Например, с помощью dotMemory.
- Для работы с SQL используйте параметризованные запросы
- Если какое-либо решение использует кэширование, убедитесь, что оно полезно для вас.